Programmieren, verdammt nochmal. Mach es. Sprichst du es?
Archiv 27.2.2011 - 22.3.2011
Why Cloud9 Deserves your Attention - browserbasierte IDE in Javascript auf Server und Client. Und Source der aktuellen Version auf github verfügbar.
Django-nonrel - NoSQL support for Django. Liefert einen ersten Ansatz in Django verschiedene NoSQL Datenbanken zu integrieren, und zwar auf Ebene des Django-ORM. Backends für MongoDB (nein Danke), AppEngine und Cassandra sind in der Mache. Besonders Cassandra interessiert mich im Moment.
WordPress › Really Static « WordPress Plugins. Mal weggeblogged, weil man damit direkt statische Seiten aus Wordpress generieren kann (ginge auch mit WP Super Cache und dessen directly cached pages, aber die werden dabei nicht automatisch aktualisiert) und vielleicht wäre das auf Dauer mal ein interessanter Weg. Ok, ich müsste wahrscheinlich auf einige Elemente verzichten, damit das ganze auch ohne "Artefakte" funktioniert - aber viele davon sind eh eigentlich verzichtbar. Zum Beispiel wäre eine Tag Cloud auf dem Stand des letzten Renderings eingefroren, wenn sie Teil der Seite ist. Genauso wie Angaben wie "letzte Kommentare" oder "letzte Posts". Dito mit Kalendern, die auf neueren Seiten mehr markierte Tage haben wie auf älteren Seiten. Das ist auch der Hauptgrund warum ich bisher immer wieder von baked Sites abgekommen bin - andererseits, sind diese Problemfälle für ein Blog wirklich wichtig?
Vundle 0.7 is out. Ich benutze ja normalerweise Pathogen, aber Vundle hat ein paar Eigenschaften die es doch recht interessant machen - vielleicht sollte ich doch mal damit rumspielen. Andererseits habe ich an meiner Vim-Installation schon länger keine Updates und Änderungen mehr gemacht. Aber da jetzt alle vim.org Scripts auf GitHub liegen, ist die GitHub-Integration von Vundle sicherlich sehr interessant.
Gefüllte Paprika im Tomatenbett
Klingt gut, oder? Schmeckt auch gut. War diesmal auch nicht so fürchterlich aufwändig, das Essen, allerdings muss man schon mit mehreren Töpfen und Pfannen (ok, ein Topf, eine Pfanne) rumwerkeln. In Meinem Fall war der Topf eine Kasserole, weil die Paprika wirklich riesig waren. Was ich reingetan habe:
- 2 große Paprika
- 250g gemischtes Hack
- 100g Schafskäse
- eine Handvoll Oliven (schwarz, natur, ohne Kern)
- 6 Tomaten
- Tomatenmark
- ein halbes Bund Basilikum
- 1 Zwiebel
- 1 1/2 Knoblauchzehen
Die Zubereitung ist recht simpel, man sollte einen großen Topf oder eine Kasserole bereithalten, in der man die Paprika bequem aufstellen kann. Ansonsten ging es so:
- Zwiebeln kleinhacken, Knoblauch kleinhacken, beides auf einen Teller
- Oliven kleinhacken, auf einen Teller
- Tomaten kleinschnippeln, auf einen Teller
- Basilikum kleinhacken, auf einen Teller
- Ofen schon mal auf 200° einstellen, damit er vorheizen kann
- Pfanne mit Olivenöl heiß machen>
- Zwiebeln und Knoblauch in der Pfanne glasig braten
- Gehacktes hinzupacken, krümelig braten (so wie für Bolognese - einfach mit dem Pfannenwender immer wieder die Klumpen teilen)
- wenn Gehacktes schön gebraten und mit dem Zwiebeln und Knoblauch gemischt ist die Oliven rein
- Temperatur runter und etwas von den Tomaten rein (Menge so 1-2 Tomaten), etwas Tomatenmark rein, mischen, Deckel drauf, 5 Minuten kochen lassen, abschmecken mit Gewürzen (bei mir Oregano, Thymian, Pfeffer, Salz)
- Deckel runter, Temperatur etwas hoch, Schafskäse rein und gut untermischen, schmelzen lassen
- Wenn Schafskäse gut unter das Hack gemischt, die Platte ausstellen
- zwei Paprika die Köpfe abschneiden, Kerngehäuse raus, die "Rippen" raus
- die Paprika mit der Hackmasse füllen, die Köpfe (vorher dort auch Kerngehäuse und Stiel entfernen, bleibt im Prinzip nur ein Ring über) zudecken
- in den großen Topf die restlichen Tomaten und das Basilikum verteilen, die Paprika da reinsetzen
- Tipp: wenn die nicht stehen bleiben wollen, mit Rouladennadeln unten rein ein Dreibeinstativ für die Paprika machen, dann hält das
- das ganze in den vorgeheizten Ofen und 20 Minuten schmoren
- nach den 20 Minuten rausnehmen und auf Teller, die Tomaten und Basilikum mit einem Dreimix pürieren
Bei mir wie üblich mit Brot, aber da gehen ganz wunderbar Nudeln oder Reis dazu. Das ergibt übrigens nicht so einen puddingweichen Paprika, der sollte ruhig noch Biss haben. Und die Füllung ist nicht der übliche Betonklotz, sondern eher vergleichbar mit einer dicken Bolognese. Bei mir gabs dann noch ein Bier dazu, einfach weil das Wetter draußen ganz laut "Bier" gesagt hat mit der ganzen Sonne heute.
Adobe Photoshop Lightroom 3 * Exporting using Publish Services. Tja, Adobe hat Photoshop.com - und gerade erst dieses ausgeweitet. Und propagiert es als eine bessere Alternative zu Flickr. Wie ernst es Adobe damit ist, sieht man an den Publish Services in Lightroom 3. Es werden von Hause aus Facebook, Flickr und SmugMug angeboten. Selbst auf der Lightroom Exchange habe ich nichts zur Anbindung von Photoshop.com gefunden. Klasse gemacht, Adobe. Voll glaubhaft.
Datenschützer: Piwik statt Google Analytics - das ist doch mal ein Anfang, konkrete Vorschläge was Sitebetreiber denn machen sollen, wenn sie Statistiken wollen. Sollten wir uns auf der Arbeit wohl mal näher angucken, um es Kunden die nach Statistiken fragen zu empfehlen.
After Church Club

Endlich mal wieder geschafft am Sonntag in den Hot Jazz Club zu kommen. Tom's Anmoderation: "Heute mit mir, es gibt also Blues. Und nur Blues. Da könnt ihr euch garnicht wehren.".
Kiepenkerle (Kiepenkerls?)



Die Kiepenkerle sind ja sowas wie ein Wahrzeichen aus Münster. Die beiden hier waren vor der Lamberthi-Kirche als ich da vorbeispazierte. Der aus Stein ist immer da, der andere macht Stadtführungen. Hauptsächlich für Juliana fotografiert - den Kiepenkerl am Spiekerhof kennt sie schon. Und ja, ich weiss, eigentlich sind das keine Kiepenkerle, denn sie tragen ja keine Kiepe, sondern sind nur die Kerle.
Update: hab da mal den Kiepenkerl vom Spiekerhof mit drangepackt.
Türfiguren




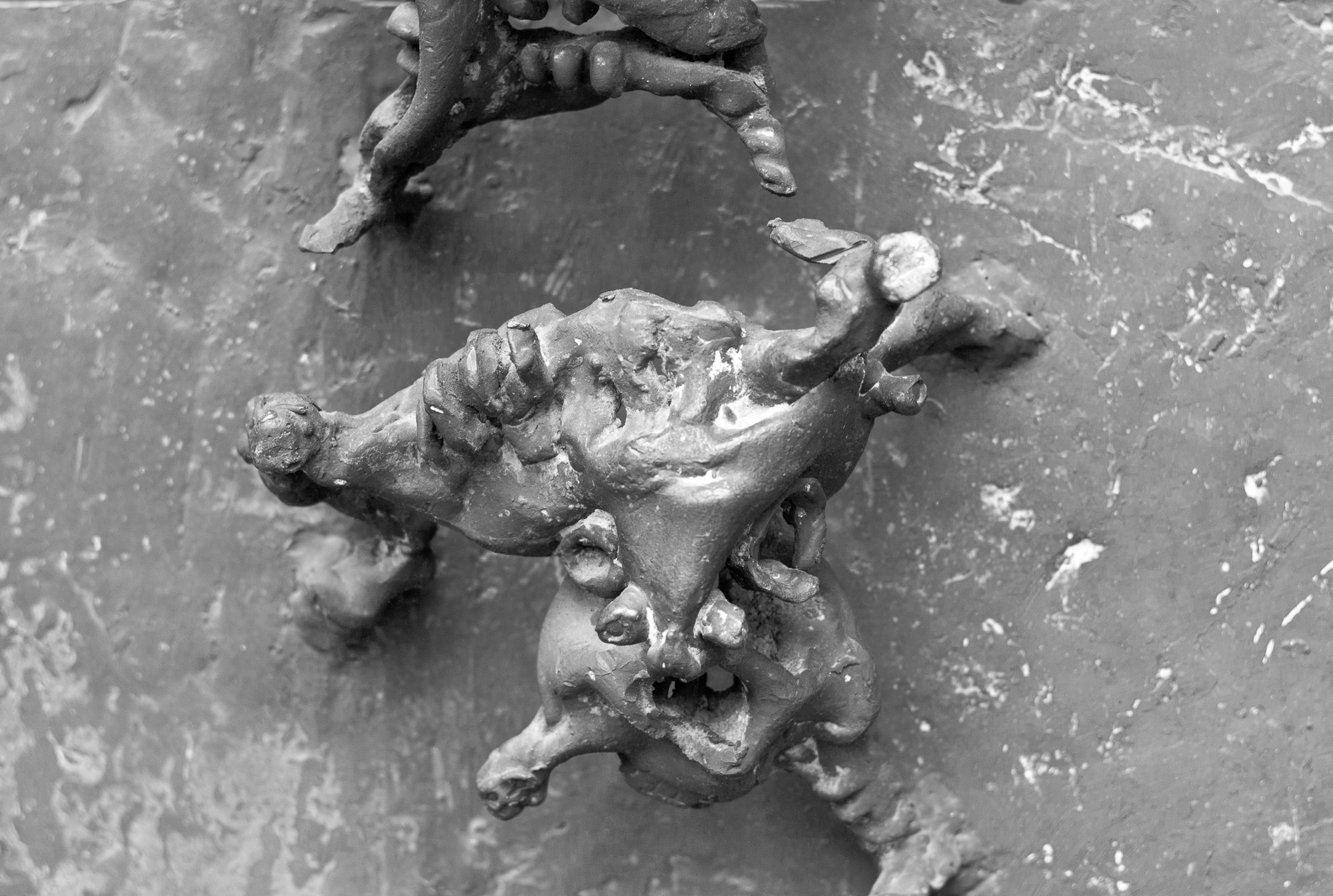


Diese Türfiguren wurden von Berndhard Kleinhans geschaffen und befinden sich an der Überwasserkirche in Münster am Seiteneingang auf der Südseite. Aufnahmen mit der Leica M8 und dem Zeiss C-Biogon 2.8/35mm.
Durch das Hinzufügen von zusätzlichem Code zu einer digitalen Musikdatei konnten sie ein auf CD gebranntes Lied in ein Trojanisches Pferd verwandeln. Wenn dieses Lied auf dem Autoradio abgespielt wird, kann es die Firmware des Autoradios ändern und Angreifern einen Einstiegspunkt bieten, um andere Komponenten des Autos zu verändern.
via With hacking, music can take control of your car | ITworld.
Satellite Photos - Japan Before and After Tsunami - Interactive Feature - NYTimes.com. Slider nach links und rechts schieben.
Programming Languages - Progopedia - Encyclopedia of Programming Languages. Das war das Programmiersprachenwiki das ich letztens gesucht hatte als mal wieder in der Wikipedia der Löschwahn um sich schlug. Hatte ich glaube ich schon im alten Blog.
Instagram hat jetzt offizielle APIs. Ist ganz an mir vorbeigegangen. Damit könnte ich vielleicht auf Dauer mal an Tumblr vorbei kommen um meine Instagram-Bilder in die Seitenleiste zu bekommen. Andererseits tuts Tumblr in letzter Zeit ganz gut und warum was funktionierendes ändern (der Fluch jeglicher Weiterentwicklung - good enough).
pdict.py at master from segfaulthunter/sandbox - GitHub. Eine PersistentHashMap für Python - also eine funktionale Datenstruktur, welche keine Veränderungen zulässt, sondern eine neue Struktur mit minimaler Änderung gegenüber einer bestehenden Struktur mit Substruktur-Sharing zur originalen Struktur liefert. Eine recht interessante Implementierung. Gibt auch nähere Erläuterungen zu den Ideen dahinter. Und eine alternative Implementation der gleichen Idee.
ShutterSnitch. Interessante kleine App mit der man Bilder über WiFi auf dem iPad empfangen und automatisch mit Metadaten und Geocodierung versehen kann - könnte eine recht interessante Kombination mit einer EyeFi-Karte in meiner Sony oder meinen Panasonics sein (die M8 kann leider nicht mit EyeFi - der SD-Slot ist bei der M8 zu knapp für die EyeFi ausgelegt und der Metallbody blockt zu viel vom schwachen Signal). Einfach die Kamera koppeln, iPad in den Rucksack und rumlaufen und schnappschießen und zwischendurch das iPad als extra-großen Lichtkasten benutzen.
Rob Galbraith DPI: Alex Majoli points and shoots. Nur mal so als Erinnerung, dass eben der Fotograf die Bilder macht und nicht die Kamera. Also die Gestaltung des Bildes. Und ja, nicht immer ist "flache Schärfenebene" die Antwort auf "was macht ein gutes Bild aus".
HowTo: Using Radio2. Tja, ok, ich verstehe seine Motivation. Aber nunja - ich klicke auf das "Press This" Bookmarklet vo Wordpress und schreibe einen Satz - das Bookmarklet-Formular hab ich mit JavaScript angepasst und Custom Post Types (in diesem Fall Aside) macht den Rest. Und oben hab ich schon ein Linkblog - und einen eigenen Feed hat es auch. Und schnell ist das ganze ebenfalls, Enclosures sind auch fix machbar und Tagging geht auch gleich. Sorry, Dave, aber irgendwie hab ich das alles schon! Update: hab einfach mal einen Twitter-Account eingerichtet und schiebe da jetzt neue Posts rein. Mal gucken was so draus wird.
Threads sind ein Hammer, aber nicht jedes Problem ist ein Nagel
Wer mal herzhaft lachen will: Node JS and Server side Java Script. Da meckert jemand aus dem Java-Lager darüber, das Node.JS ja nun wirklich nicht ernstzunehmen sei und produziert doch selber gleich das beste Beispiel, warum sowas wie Node.JS (und viele andere Alternativen für Serverprogrammierung) existieren - denn der Java Code wird mit jedem Schritt länger und länger. Und selbst nach mehreren Iterationen für ein in Node.JS (oder z.B. mit gevent in Python) ziemlich simpel zu realisierendes Beispiel werden in den ersten Kommentaren gleich ein paar Fehler und Lücken im Java Code angesprochen.
Versteht mich nicht falsch - Java hat eine Menge von guten Lösungen für Programmierung mit multiplen Threads in der Standard-Library. Warscheinlich von allen derzeit verfügbaren Sprachen die größte Auswahl an Möglichkeiten mit multiplen Threads zu programmieren. Aber wie so oft im Leben: Threads sind nicht die Antwort auf alle Fragen der Parallelisierung. Besonders wenn es in die Richtung von hoher Request-Last geht, ist die Einschätzung in den Kommentaren das 20K Threads schon sehr hoch sind lächerlich - erzählt das mal den Programmierern von Eve Online, in der jedes Schiff in derem virtuellen Universum als Microthread modelliert wird.
Java ist als Plattform sehr interessant, eben weil es viele Low-Level-Libraries mitliefert mit denen man sehr interessante Sachen machen kann - und die hilfreich sind um vernünftige Highlevel-Konstrukte darauf aufzubauen. Zum Beispiel im Zusammenspiel mit Sprachen wie Clojure oder Scala wird dem Threadmonster einiges an Schrecken genommen. Aber manchmal ist die Antwort eben nicht der Thread, sondern asynchroner IO (sowohl bei Festplattenzugriffen und Netzwerkzugriffen) und die intensive Nutzung von Coroutinen oder Continuations.
Auch das Unverständnis der Java-Programmierer auf den Ansatz das Multi-Core Problem einfach mit mehreren parallelen Prozessen und Message-Passing zwischen diesen zu lösen ist in 2011 ziemlich seltsam - denn schließlich waren 2009 und 2010 die Revival-Jahre für Erlang (nicht vergessen, die Sprache existiert schon sehr viel länger) und gerade die zentrale Idee von Erlang ist ja das Netz- und CPU-übergreifende Message-Passing als Standard zu setzen um eine sehr einfache Parallelisierbarkeit und Skalierbarkeit zu bekommen.
Java-Programmierer erinnern mich immer wieder an die Cobol-Programmierer meiner Anfangszeit, die in jeder Sprache und jeder Programmierweise ganz gezielt die Sachen rauspickten und kritisierten, die in Cobol eben anders (und manchmal sogar vielleicht etwas einfacher) gelöst waren - aber dann gnadenlos auf die Schnauze fielen wenn sie damit reale Probleme ausserhalb der Cobol-Komfortzone lösen mussten.
Das Beste von Java ist die JVM und damit eine Plattform die gerade die Multiparadigmen und -sprachen Ansätze möglich machen mit denen man dann für Probleme die Werkzeuge einsetzen kann, die ihnen angemessen sind. Und selbst dann ist manchmal die Antwort trotzdem Node.JS oder ein anderer kleiner, schlanker, asynchroner Server. Denn selbst mit einer großen Sammlung verschiedenster Hämmer wird man sich für die Schraube trotzdem einen Schraubendreher holen.
Die Risiken der Technik kann man nicht abschaffen. Wohl aber den Umgang damit ändern. Anlagen wie Atomkraftwerke, die zu unfassbaren Schäden führen, sollte kein Staat betreiben. Und Menschen, die mit solchen Anlagen ihr Geld verdienen, wie unsere werte Atombranche, sind klar als verantwortungslose Lobbyisten zu brandmarken. Sie haben die Lage in ihren Reden noch im Griff, während hinter ihnen bereits die Reaktorhalle auseinanderfliegt
via Dieses Vertuschen und Verzögern ist ein unfassbarer Skandal: Die Methoden der Atomlobby - taz.de.
Minestrone für die ganze Familie
Tja, ich hab mich einfach geweigert weniger als jeweils ein ganzes Gemüse zu nehmen, und schwupp da war es dann doch eine ganze Menge. Also besser einen großen Topf bereithalten! Schmeckt aber verdammt gut, die Minestrone. Was ich reingepackt habe:
- 1 Paprika
- 1 Zucchini
- 3 Tomaten
- 3 Stangen Sellerie
- 1 große Möhre
- 3 kleine Kartoffeln
- 100g durchwachsener Speck
- Parmesan mit Rinde
- 150g grüne Bohnen
- 2 violette Zwiebeln
- 2 Knoblauchzehen
- 1/2 Bund Basilikum (frisch)
- 1 Esslöffel Tomatenmark
- eine Handvoll Oliven (schwarz, entkernt, natur)
- 1l Gemüsebrühe
- 50g Butter
- Olivenöl
- ca. 50g Spaghetti (kleingebrochen)
Die Zubereitung ist echt Arbeit und in der ersten Phase gibts nicht viel Ruhe. Und am besten die Gruppierung der Gemüse wie unten angegeben, denn so kommen die nacheinander in den Topf - es wird nämlich erstmal alles vorgebraten. Aber ansonsten ist es eigentlich ganz einfach:
- Speck würfeln und auf einen Teller
- Zwiebeln und Knoblauch würfeln und in ein Schälchen
- Kartoffeln, Sellerie, Möhren würfeln und in eine Schüssel
- Bohnen kleinschnippeln und in eine Schüssel
- Paprika und Zucchini würfeln und in eine Schüssel
- Topf aufheizen mit Olivenöl und der Butter
- Speck 2 Minuten darin anbraten (fleißig rühren!)
- Zwiebeln mit Knoblauch rein in den Topf und 2 Minuten braten (fleißig rühren!)
- Kartoffeln, Sellerie und Möhren in den Topf und 2 Minuten braten (fleißig rühren!)
- Bohnen in den Topf und 2 Minuten braten (fleißig rühren!)
- Zucchini und Paprika in den Topf und 2 Minuten braten (fleißig rühren! wenn der Arm sich anfühlt als ob er abfällt: das ist normal, weiterrühren!)
- Deckel drauf, Temperatur runter und 15 Minuten das Gemüse garen lassen, zwischendurch immer mal wieder umrühren
- Arm kann leider nicht ausruhen, denn jetzt werden die Tomaten gewürfelt und wenn gewünscht die Oliven kleingeschnitten (ich lass sie immer ganz bei Suppen).
- Bevor die 15 Minuten um sind die Oliven reinwerfen (so nach halber Zeit)
- Basilikum kleinschneiden
- wenn die 15 Minuten um sind die Gemüsebrühe in den Topf, umrühren
- Tomatenmark, kleingehackte Tomaten und Basilikum rein, abschmecken mit Pfeffer und Salz
- Parmesanrinde reinwerfen (ich bind die mit Küchengarn an, damit sie leicht wieder rauszufischen ist)
- aufkochen lassen, Temperatur runter und eine Stunde leise köcheln lassen (bei meinem Monstertopf reicht da ein halber Punkt am E-Herd)
- Parmesanrinde rausfischen und wegwerfen
- Spaghetti rein und 10 Minuten kochen lassen
Gegessen wird das ganze dann bei mir einfach mit Brot dazu. Man kann auch Sauerrahm in die Suppe tun, oder ganz italienisch Parmesan drüberreiben. Dazu ein Glas Wein.
Re: Factor: Google Charts - ich sollte wirklich mehr mit factor machen, immer wenn ich wieder mal sehe wie praktisch eine visuelle repl ist (in Factor können auch grafische Repräsentationen von Objekten eingebettet werden in die normalen Ausgaben, ähnlich wie bei alten Lispmaschinen) reizt es mich.
Kernschmelze in Japan immer wahrscheinlicher
BBC News - Japan earthquake: Explosion at Fukushima nuclear plant. Das wars dann mit den Hoffnungen, dass es vielleicht doch noch glimpflich abgehen könnte. Und immer noch rennen Leute rum die behaupten, sowas könne natürlich nie bei uns passieren, weil hier ist ja alles viel sicherer. Komischerweise erinnere ich mich durchaus an Störfälle in Kühlsystemen, die erst lange nach Auftreten zugegeben wurden - und der Ausfall des Kühlsystems ist in Japan das Problem, der Tsunami und das Erdbeben waren dafür nur der Auslöser.
Was ich mich allerdings frage, wie wird die Katastrophe in Japan unsere Wahrnehmung der Atomenergie verändern? Bei Tchernobyl und vorher Harrisburg war Geheimhaltung vergleichsweise einfach - aber Japan ist ein Land in dem alle Bewohner hochtechnologisiert sind. Der witz über mindestens 5 Kameras pro Japaner ist vielleicht übertrieben, aber die Anzahl dürfte hoch genug sein um eine Geheimhaltung mehr oder weniger ad absurdum zu führen. Und die hohe Integration in das Internet führt zu Veröffentlichungskanälen die bei Harrisburg noch undenkbar und auch bei Tchernobyl nur für Utopisten vorstellbar waren.
Sicherlich werden jetzt wieder Energiekonzerne und Regierung Schulterschluß zeigen und davon reden, dass ja Erdbeben und Tsunamis in Europa kein Problem darstellen. Und damit komplett am eigentlichen Problem vorbeiargumentieren, denn wie oben gesagt, Kühlsysteme können nicht nur wegen Erdbeben und Tsunamis ausfallen. Von daher ist ein solches Problem durchaus auch bei uns denkbar, wenn das Kühlsystem auf andere Weise ausfällt. Und warum sollten wir unseren regelmäßig beim Lügen erwischten Energiekonzernen (und der Regierung) mehr glauben als dem - genauso fürs Lügen bekannten - japanischen Energiekonzern?
Es wird schwer werden für Politiker bei sowas noch glaubwürdig zu lügen. Und vielleicht, ganz vielleicht, wachen in Europa die Menschen auf von ihren Wunschvorstellungen, die Atomenergie sei so sicher.
consistency and ecosystem opportunities - Twitter API Announcements ist eine Mail mit der Twitter so ziemlich jeglichen Boden der Realität verlässt. Zur Erinnerung: Twitter ist dieser putzige Dienst auf den man 140 Zeichen Nachrichten scchicken kann - und ich red das garnicht lächerlich, es ist oft ganz praktisch dort zu suchen wenn aktuell was los ist. Aber wenn ich dann diese Moppelkotze über "prevent diffusion of user experience" und anderes Bullshit Bingo in der Mail lese kann ich mich nur noch fragen welches Kraut die rauchen. Real steht dahinter wohl eher der Versuch die Plattform dicht zu ziehen um sie stärker zu kontrolieren und auszuschlachten - z.B. der Aufruhr über diesenn absurde Dickbar in Twitter hat da wohl leichte Panik bei Twitter ausgelöst. Denn wenn alle User vom offiziellen Client weg gehen, guckt sich keiner mehr die gekauften Trends an ...
Python Tools for Visual Studio. Wer auf Windows sitzt und Zahlenfresser ist - SciPy und NumPy sind da jetzt direkt in der .NET Plattform verfügbar mit diesen Tools. Und ich frage mich, warum Apple sowas nicht mit XCode mitliefert, denn das würde sicherlich im Umfeld der Universitäten Anklang finden (man denke nur an Sage).
ABCL - Release notes v0.25. Neue Version raus und ABCL entwickelt sich immer mehr in eine wirklich brauchbare Common Lisp Implementation. Dadurch, dass es auf der JVM läuft, hat man auch leichten Zugriff auf viele Libraries (sofern man es denn will) und seit 0.24 läuft auch Quicklisp sauber mit ABCL und damit hat man auch leichten Zugriff auf viele Common Lisp Libraries. Bei den CL Libraries hakt es aber leider etwas, da viele Programmierer ABCL nicht berücksichtigen (und gerade im CLOS Bereich noch Defizite sind).
BBC News - Voyager: Still dancing 17 billion km from Earth. Weils immer mal wieder vergessen wird und weil es immer noch eine der faszinierendsten Missionen ist - die Voyager Sonden sind nämlich immer noch aktiv im Dienst. Und sie liefern immer noch wichtige Beiträge zur Forschung. Mehr davon!
J Source ist jetzt unter GPL3 verfügbar. Die verrückteste Programmiersprache in aktiver Benutzung ist jetzt noch eine Nummer zugänglicher. Aber vorsicht vor dem Source: das ist zwar C, aber C von jemandem der J denkt und J schreibt und dafür nur den C-Compiler missbraucht.
blueMarine ist noch ein mir bisher unbekanntes Projekt, das Lightroom und Aperture als Inspiration nimmt. Allerdings hat es bisher keinerlei RAW-Edit-Funktionen (während Darktable non-destruktives Editieren hat), sondern konzentriert sich rein auf das Image Management. Was mir aber unter Umständen für Linux sogar entgegen käme, da ich dort meistens nur reingucken will, das Bearbeiten passiert doch meistens auf dem Mac.
darktable ist scheinbar komplett an mir unbemerkt vorbeigerauscht - eine OpenSource Alternative zu Adobe Lightroom für Linux. Sollte ich mir wirklich mal angucken. Lightroom gefällt mir zwar sehr gut, aber macht absolut nichts da eine Alternative für zu kennen, denn ob mir Adobe in späteren Versionen immer noch gefallen wird ist ja nicht gerade garantiert ... (und für Linux werde ich sowieso immer eine Alternative brauche solange Adobe kein Linux unterstützt)
fantasm - Project Hosting on Google Code. Unbedingt mal angucken, eine Workflow-Engine in Python. Sowas könnte für Projekte auf der Arbeit recht interessant werden.
Seltsame Phänomene in iPhoto
Ich benutze das ja nur als Bilderspeicher zur Erstellung von Büchern und zum Sync auf mein iPhone und iPad, daher ist mein iPhoto eher unwichtig für die Fotoverwaltung - aber im Moment habe ich ein Phänomen, das mich ziemlich zur Verzweiflung treibt: ich habe eine CD von ganz normalen Jpegs importiert. Dann habe ich ein Album angelegt und die Bilder reingepackt. Und jetzt behauptet iTunes beim Sync immer, dieses Album wäre leer. Der Import ist auch als eigenständiges Ereignis im iPhoto. Auch für dieses Ereignis behauptet iTunes im Sync Panel es wäre leer (0 Bilder). Dementsprechend werden bei "Alle Bilder synchronisieren" auch brav alle Bilder übertragen - dabei dann auch diese Bilder. Nur die Alben und Ereignisse, die nur aus diesen Bildern bestehen, sind nicht da. Weil iTunes glaubt die wären leer.
Was soll der Mist? Irgendwer da draußen eine Idee? Googlen hat nichts sinnvolles gebracht und diverse Sachen (löschen und neu anlegen von Alben, verschiedene Arten die Alben anzulegen etc.) hab ich auch schon probiert. Ziemlich seltsam das ganze. iLife ist ja ganz nett solange es funktioniert, aber wenn Probleme auftreten ist das ganze Zeug nahezu komplett nicht diagnostizierbar. Was mir ziemlich wurscht wäre, wenn ich es nicht dummerweise für den Sync mit meinem iPhone und iPad bräuchte ...
Ein Grund warum ich doch lieber bei Lightroom bleibe, da weiss ich wo die Bilder liegen und die Datenbanken sind normales sqlite, da kann ich notfalls auch Hand anlegen. Und wenn sie im Eimer sind, kann ich alles aus Bildern und Sidecar-Files rekonstruieren. Aperture streiche ich auch gleich mal lieber von der Liste, dessen Bilderverwaltung klingt mir allzusehr nach der von iPhoto ...
Schon peinlich, wenn ein Tool von Adobe verlässlicher und vertrauenserweckender ist, als das was Apple abliefert. Ganz besonders da iLife ja angeblich Narrensicher ist - bei Problemen und der notwendigen Fehlerbehebung ist das dann eher ein Fall von "no user-serviceable parts inside".
harukizaemon/hamster. Immutable Threadsafe Datastructures - für Ruby. Man kann sie also nicht ändern, aber dafür bekommt man neue, geänderte Versionen zurück. Ideal um sie z.B. über Threadgrenzen hinweg zu benutzen. Clojure hat sowas von Hause aus, Scala seit 2.8 ebenfalls. Ich hätte sowas gerne für Python ...
Pyjamas - Python Javascript Compiler, Desktop Widget Set and RIA Web Framework. Hatte ich im alten Blog schon mal, aber a) hat sich ne Menge getan und b) kams mal wieder heute hoch als Thema, also nochmal geblogmarkt.
Mal angucken: pqc - PostgreSQL Query Cache. Ein PostgreSQL Proxy, der Abfragen über eine Memcache-DB cached um Performance für wiederkehrende Abfragen zu verbessern. Dadurch, dass er als Proxy arbeitet, kann er auch Anwendungen beschleunigen, die nicht von Hause aus schon Caching selber realisieren.
Welches Arschloch auch immer bei Apple für das Design der hahnebüchen schlechten App-Sortierung in iTunes verantwortlich ist (ehrlich, wie kann man nur so komplett verblödet sein, das schon ziemlich hakelige Sortierinterface für den Homescreen nahezu perfekt gleich dämlich in iTunes nur mit der Maus nachzubilden?), selbiger "Designer" gehört geohrfeigt, getreten und gefeuert. Wenn ich 20 Minuten meine Apps sortiere, erwarte ich beim Klick auf "Anwenden", dass es auch angewendet wird. Keinesfalls erwarte ich, dass alle Icons in ihre Ursprungsposition vor meinen 20 Minuten zurückspringen. Und nein, das ist nicht das erste Mal, dass ich dieses armselige Interface für die App-Sortierung verfluche. Bah.
Apple kann einfach keine Verschlüsselung
Ich bin mal wieder drauf reingefallen und dachte, schalte doch die Verschlüsselung der iPad Backups an. Schön blöd. Ich hätte nach den Debakeln mit dem verschlüsselten Homeverzeichnis gewarnt sein müssen. Aber natürlich hab ichs doch mal wieder gemacht. Hat alles geklappt, bis jetzt heute der Backup Mist gemacht hat - er hing im ersten Step und ging einfach nicht weiter. Möglicherweise korrupte Backupfiles auf dem Mac. Ok, der Standard dabei ist einfach das Backup in den Einstellungen unter Geräte wegzuwerfen und ein neues zu machen. Nur geht das nicht, wenn man die Verschlüsselung an hat - er meckert, natürlich erst nachdem alle Steps durchlaufen sind, dass er keine Backups machen kann, weil keine Session mit dem iPad gestartet werden kann. Häh?
Und ich kann natürlich das Kennwort nicht zurücksetzen - er behauptet immer es wäre falsch (auch schon bevor ich das Backup gelöscht habe). Mein Verdacht: das Kennwort wird gegen das Backup getestet und wenn da keines ist, oder dieses defekt ist, kann man natürlich keine erfolgreiche Prüfung machen. Zurücksetzen des Kennwortes geht nicht, neue Backups anlegen geht nicht und dem iTunes einfach das iPad vergessen lassen geht auch nicht. Bevor jemand meint mir erzählen zu müssen ich wüsste das Passwort nicht: iTunes speichert auf Wunsch das Passwort im Schlüsselbund und ja, das Passwort ist das welches ich eingebe. Und ja, das ist garantiert das richtige - die Geräte-Kennung wird als Accountname an dem Passwort gespeichert. Und nein, genau dieses Passwort wird natürlich nicht akzeptiert ...
Lösung laut Apple? Komplett das iPad zurücksetzen und neu einrichten. Ganz tolle, ganz großartige Idee. Klar, viele Daten die ich habe liegen auf meinem Mac, aber im Laufe der Zeit sind eben auch Daten so dazugekommen, die eben nicht auf dem Mac liegen. Und die würde man schon gerne irgendwie übernehmen.
Wohlgemerkt, normale Sicherungen und Restores tuns - und bei unverschlüsseltem Backup kann man auch bei kaputten Backups einfach ein neues machen lassen. Nur eben nicht wenn man die Verschlüsselung an hat.
Ehrlich gesagt lässt mich diese erneute Erfahrung mit der Unfähigkeit Apples vernünftig stabil laufende Verschlüsselungslösungen zu bauen doch eher skeptisch auf deren full-disk Encryption im kommenden 10.7 schauen ...
Update: nach ein paar Experimenten (testweise an anderem Rechner angehängt, Backup des iPad aus der TimeMachine Sicherung rekonstruiert und damit versucht) vermute ich, das Kennwort wird auch auf dem Gerät vermerkt - und dieser Vermerk scheint korrumpierbar zu sein. Denn auch an einem anderen Gerät wird das definitiv korrekte Kennwort als falsch abgewiesen und auch ein anderes Gerät will zwingend verschlüsseltes Backup machen (macht ja auch Sinn, sonst käme man ja trivial an die Daten über ein Backup auf ein anderes Gerät dran). Das Problem ist auch nicht, dass es sich absichert gegen Manipulation - das Problem ist, dass dieser Mist kaputt gehen kann und zwar ohne äußere Anzeichen - die Backups haben bisher immer problemlos funktioneirt, sie sind nur jetzt plötzlich nichts mehr wert (genauso wie die Daten auf dem Gerät).
The Sinclair ZX81: 30 years old today. Happy Birthday, oller Plastikkasten. Watt hab ich die Kiste geliebt und was für bekloppte Projekte darauf gestartet. Am Start mit 1 Kilobyte Speicher, später dann mit der tollen Erweiterung von 16 Kilobyte - man durfte nicht zu stark auf den Tisch hauen, sonst wackelten die Steckverbindungen und der Rechner machte einen Reset. Und die Kiste hat mir immerhin meinen ersten (und einzigen) Artikel in der c't eingebracht! Nach dem ZX 81 kam dann (von dem Geld aus dem Artikel) der ZX Spectrum mit gigantischen 48 Kilobyte Speicher. Danach wurds langweilig mit PCs. Erst in den 90ern kamen dann Macs bei mir.
Pferderouladen mit Ratatouille
Tja, das war das heutige Kochexperiment. Teilerfolg, denn ich habe mich in Mengen völlig verkalkuliert (kein Problem, gibt ja einen Gefrierschrank und leckere Rationen für einen anderen Tag sind ja auch was feines) und das Ratatouille ist mir irgendwie doch arg verkocht heute. Aber das kommt davon wenn man gleich mit mehreren Pötten hantieren will, das klappt beim ersten Mal noch nicht so richtig. Aber die Rouladen waren klasse - allerdings gigantisch. Nur zu empfehlen wenn man großen Hunger hat! Ich hab gleich etwas auf Vorrat gekocht (einen Bräter für nur eine Roulade zu benutzen wäre Quatsch), gibt ca. 3 Gerichte:
- 3 Rouladen vom Pferd (vorsicht, die Dinger sind eher XXL Format, eine reicht da locker pro Person!)
- 300g gemischtes Hack
- entkernte schwarze Oliven "natur" (so 10-15 Stück, kommt halt auf die Größe an - und den Geschmack)
- 1 Zwiebel
- 3 Knoblauchzehen
- Senf (ich hatte einen schönen scharfen Feigensenf, aber einfacher mittelscharfer tuts wohl auch), 3 Esslöffel ungefähr
- eine Möhre
- halbe Sellerieknolle
- ein Loorbeerblatt
- 2 Nelken
- etwas Pfefferkörner
- 100ml Rotwein
- 200ml Brühe (wahrscheinlich hätte es mehr sein dürfen, Soße war etwas dürftig)
- 3 Paprika
- eine Aubergine
- eine Zuchini
- 1-2 Tomaten
- Basilikum, Oregano, Thymian, oder was sonst noch so an Gewürzen gefällt
- Pfeffer und Salz wie üblich
- Olivenöl
Bei der Zubereitung fängt man am besten mit den Rouladen und deren Füllung an - denn das dauert eh am längsten und die Rouladen schmoren dann im Ofen, da kann man dann in Ruhe das Ratatouille vorbereiten.
Übrigens empfiehlt sich für das Gericht der Besitz eines Bräters - das sind diese gigantischen und sauschweren Töpfe in ovaler Form, die man von Muttern vom Braten her kennt. Teuer, schwer, lästig, aber bei der Größe der Pferderouladen denkt gar nicht erst über einen normalen Topf nach, nehmt gleich einen Bräter.
- Zwiebel und Knoblauch kleinschnippeln
- Oliven kleinschnippeln
- weil wir dabei sind Auberginen auch schon mal kleinschnippeln und in Salzwasser einlegen (manchmal sind die Bitter, die brauchen also ein Bad vor der Nutzung)
- Hack, Zwiebeln, Knoblauch und Oliven ordentlich vermengen. Da kann man auch ruhig schon Gewürz (Thymian, Oregano) rein packen. Im Prinzip die Verteilung: Fleisch würzig, Gemüse eher milder, also hier die etwas kräftigeren Sachen.
- Rouladen glatt ausbreiten (und wundern worauf man das hinkriegt - die Teile sind gigantisch!)
- jede Roulade mit einen Esslöffel Senf bestreichen
- dann Füllung drauf verteilen
- Rouladen aufrollen und mit Rouladenringen oder Rouladennadeln fixieren (Ringe gingen bei mir einfacher - zwei pro Roulade, wegen der Größe)
- Sellerie, Möhre (und bei Wunsch ne weitere Zwiebel!) kleinschnippeln
- Backofen schon mal auf 170° einstellen und vorheizen lassen
- Öl im Bräter heiß werden lassen, Rouladen von allen Seiten ein paar Minuten scharf anbraten
- Rouladen raus, auf Teller zwischenlagern, Sellerie und Möhren Schnipsel rein in den Sud vom Rouladen anbraten
- Nelken, Loorbeerblatt und Pfefferkörner rein
- alles schön braten, sollte ruhig am Gemüse Spuren hinterlassen
- mit dem Rotwein ablöschen (also drüberkippen)
- alles wieder aufkochen lassen
- die Brühe hineinkippen
- nochmal alles aufkochen lassen
- Rouladen wieder in den Bräter reinpacken
- die Flüssigkeit sollte nicht zu wenig unten sein, denn einiges kocht noch weg und dann werden die Rouladen trocken, also notfalls mit etwas Wasser (oder wenn man noch hat Brühe) nachfüllen
- kurz aufkochen lassen
- den Bräter mit den Rouladen ab in den Backofen und da lassen wir ihn einfach mal 1.5 - 2 Stunden. Zwischendurch sollte man mal die Rouladen umdrehen (1-2 mal).
Da jetzt die Rouladen schmoren - und das dauert! - ist jetzt eine gute Zeit etwas aufzuräumen in der Küche und all die Teller und Schüsseln sauber zu machen, die man zwischendurch verbraucht hat weil man panikartig merkte das Ablagefläche für die Greifzange fehlte, oder das Gemüse ja auch irgendwo drin auf seine Bestimmung warten musste oder ähnliches. Kurz Luft holen und entspannen, Ratatouille ist eigentlich ganz einfach. So ca. 30 Minuten vor Ende der Rouladen dann mal mit dem Rest anfangen:
- Paprika und Zucchini alles in kleine Stücke schnippeln, Auberginen extra halten, die brauchen länger (optimal würde man alle drei Gemüse extra halten)
- bei Wunsch auch eine Zwiebel und etwas Knoblauch rein - kann man einfach bei den Rouladen oben mitmachen und etwas davon abzweigen für das Ratatuille)
- Tomaten auch schon mal kleinschnippeln (wer will kann die vorher in heißen Wasser etwas vorkochen und dann pellen - ich hab mit Tomatenpelle keine Probleme und spar mir das)
- Öl in der Pfanne heißmachen
- Auberginen rein und vorbraten (hier kämen auch die Zwiebeln und der Knoblach mit rein)
- wenn die Auberginen anfangen glasig zu werden die Zucchini rein
- wenn die Zucchini anfangen glasig zu werden die Paprika und Tomaten rein
- alles ordentlich anbraten und auch schon mal etwas würzen. Die Tomaten sollen ruhig zerfallen, aber das andere Gemüse sollte in seiner Form noch erkennbar sein.
- Deckel auf die Pfanne (eure Pfanne hat doch einen Deckel, oder? Wenn nicht wirds schwierig!) und 5 Minuten garen lassen (das war mein Fehler, zu lange, wurde zu weich - die 5 Minuten sind so eine Schätzung von mir, ich hatte mehr)
Wenn das Ratatouille fertig ist, sollten auch die Rouladen fertig sein. Also die Rouladen raus aus dem Ofen und auf die Teller. Wer Soße will: einfach das Gemüse-Bratensaft-Gemisch aus dem Bräter durch ein Sieb filtern und dann etwas Wasser zum verdünnen und mit Soßenbinder Soße machen. Ist derzeit noch theoretisch bei mir, da nicht genug unten drin war um sich die Mühe zu machen, also hab ich nur etwas vom Bratenrückstand auf die Roulade getan.
Gegessen hab ich das ganze wieder wie üblich mit Brot. Dazu - da ich ihn ja eh schon offen hatte - ein Glas Wein. War sehr lecker (ok, im Restaurant hätte ich das doch arg weiche Ratatuille kommentiert, aber bei eigenen Experimenten bin ich dann doch recht tolerant mir gegenüber), nur schlichtweg eine viel zu große Portion. Und die Zeit investiert um das ganze zu produzieren stand in keinem Verhältnis zur Zeit in der ich die Portion verputzt habe. Aber hey, das Wetter war heute eh nicht so toll, da kann man auch mal solche Kochexkursionen machen.
jsFiddle ist ein sehr nett gemachter Online-Editor für Javascript, HTML und CSS. Es werden verschiedene Javascript-Frameworks unterstützt und es gibt die Möglichkeit Snippets zu speichern und mit anderen zu diskutieren. Progressing.js steht auch zur Verfügung, genauso wie eine Reihe von Tools um sie auf den Code loszulassen. Für Experimente recht cool.
Toolbox, H5 und twentytenfive sind Wordpress-Templates die auf HTML5 aufbauen. Ich sollte mir das mal angucken und schauen ob ich mein eigenes Theme nicht auf einem davon aufbaue, anstelle es vom Standard-Theme abzuleiten. Da ich derzeit ein Subtheme vom Standard Twentyten bin, könnte warscheinlich Twentytenfive am einfachsten sein - aber auch Toolbox könnte interessant sein, weil es ein wirklich minimales Theme ist, das ich als echte Basis verwenden könnte.
balupton/history.js liefert ein API zum Zugriff auf die HTML5 Historymanipulation, aber gleichzeitig unterstützt es auch alte Browser und macht da dann diese hässliche # Notation - aber eben nur dann, wenn HTML5 nicht verfügbar ist. Könnte für ein Projekt bei mir recht interessant sein.
Heute gelernt, dass es zwei-beinige Schleichen (also eigentlich beinlose Reptilien) gibt, deren Pfoten vorne als Baggerschaufeln ala Maulwurf verwendet werden: Handwühlen. Immer wenn du glaubst die Natur ist schon schräg genug, lernst du eine neue Kuriosität kennen.
Paprika-Bohnen-Suppe mit Hack
Und mal wieder eine lustige Folge aus "Kochen mit RFC1437". Heute eine richtige Männersuppe. Ok, für Männer die nicht so wild auf scharf sind. Männchensuppe dann eben.
- zwei Paprika
- eine Zwiebel (nicht zu klein)
- 4 Knoblauchzehen
- 2 milde Peperoni
- 300g Hack
- 400g Kidneybohnen (aus der Dose)
- 500ml Gemüsebrühe (bei mir wars nur 450, die restlichen 50 waren im vorigen Kochanfall)
- Tomatenmark
- Basilikum
- Koriander
- Pfeffer und Salz
- Zwiebeln kleinhacken oder würfeln (ich würfel, naja, so ähnlich wie Würfel - klein eben)
- Knoblauch klein würfeln
- Paprika klein würfeln
- Peperoni klein würfeln und sich fragen wann man sich eine Küchenmaschine kauft
- Pfanne heiß, Olivenöl rein
- Hack krümelig braten (einfach rein mit dem Hack und mit dem Pfannenwender immer wieder die Klumpen teilen bis es schöne kleine Krümel angebratenes Hack sind) - nicht ganz zuende Braten, das wird ja noch in der Suppe gekocht
- wenn Hack fertig, dann raus in den Topf damit
- Zwiebeln und Knoblauch rein in die Pfanne und glasig werden lassen
- Paprika und Peperoni rein in die Pfanne und ein paar Minuten braten zusammen mit den Zwiebeln
- das ganze Zeug raus aus der Pfanne und rein in den Topf
- halber Liter Gemüsebrühe in den Topf
- die Bohnen in den Topf
- Basilikum und Koriander in die Suppe - bei Basilikum bin ich recht großzügig
- aufkochen lassen, danach 30 Minuten köcheln lassen (also einfach nicht so großes Blubbern im Topf - bei meinem Herd reicht ein halber Punkt bei vollem Topf dafür aus), zwischendurch mal umrühren
- abschmecken und mit Pfeffer und Salz ergänzen
Das ganze schmeckt dann so ein bisschen wie ein mildes, leicht süßes Chili con Carne. Ich vermute mal mit Chiligewürz und scharfen Peperoni ist das ganze auch eine brauchbare scharfe Variante. Und lässt sich sicherlich bei den Gemüsen fröhlich variieren. Das ganze ergibt dann so ungefähr 4 normale Suppenteller.
Plagiatsaffäre: Doktorvater distanziert sich von zu Guttenberg. Nur so als Frage in den Raum gestellt (ehrlich, ich weiss es nicht!): liest ein Doktorvater nicht die Doktorarbeit seines Doktoranden?
WordPress JSON API. Keine Ahnung ob ich das jetzt wirklich brauche, aber es könnte sich irgendwann mal als nützlich erweisen - die XMLRPC oder Atom APIs sind doch relativ umständlich wenn man nur per JavaScript mal fix auf Daten aus dem Blog zugreifen will.
Feeding the Bit Bucket» Blog Archive » Common Lisp, Clojure and Evolution. Nein, Clojure wird nicht als Evolution von Common Lisp beschrieben - das ist einfach das Beispielprogramm "Evolution" aus dem Buch "Land of Lisp" in Clojure übersetzt von jemandem der mit dem Buch Clojure lernt indem er eben alle Beispiele in Clojure realisiert mit der Common Lisp Code als Basis. Und von daher eine gute Vergleichsmöglichkeit zwischen Clojure und Common Lisp. Vielleicht ja für 2 oder 3 Leser meines Blogs interessant. Ansonsten für mich als Blogmark um später wieder draufzugucken.
Naked Password - jQuery Plugin to Encourage Stronger Passwords. Ja, das ist das, was draufsteht. Das Internet ist sehr, sehr seltsam.
Wochenmarkt in Münster



Bei dem tristen Winterwetter im Moment ist der Wochenmarkt nicht nur eine gute Gelegenheit das Essen zu bekommen, das ich mir am Wochenende zubereiten will, sondern auch ein echtes Fest für die Augen. Ich brauche Farben! (Bilder mit der Sony NEX-3 und dem 2.8/16mm Objektiv)